Я запускаю эту команду:
pg_dumpall | bzip2 > cluster-$(date --iso).sql.bz2
Это занимает слишком много времени. Я смотрю на процессы с top. Процесс bzip2 занимает около 95%, а postgres - 5% одного ядра. В wa вход низкий. Это означает, что диск не является узким местом.
Что я могу сделать, чтобы повысить производительность?
Может, пусть bzip2 использует побольше ядер. На серверах 16 ядер.
Или использовать альтернативу bzip2?
Что я могу сделать, чтобы повысить производительность?
Есть много алгоритмов сжатия, и bzip2 один из самых медленных. Простой gzip имеет тенденцию быть значительно быстрее, обычно не намного хуже сжатия. Когда скорость важнее всего, lzop мой любимый. Плохая компрессия, но ох, как быстро.
Я решил немного развлечься и сравнить несколько алгоритмов, включая их параллельные реализации. Входной файл - это результат работы pg_dumpall на моей рабочей станции, файл SQL размером 1913 МБ. Аппаратное обеспечение - более старый четырехъядерный i5. Время - это время просто сжатия. Параллельные реализации настроены на использование всех 4 ядер. Таблица отсортирована по скорости сжатия.
Algorithm Compressed size Compression Decompression
lzop 398MB 20.8% 4.2s 455.6MB/s 3.1s 617.3MB/s
lz4 416MB 21.7% 4.5s 424.2MB/s 1.6s 1181.3MB/s
brotli (q0) 307MB 16.1% 7.3s 262.1MB/s 4.9s 390.5MB/s
brotli (q1) 234MB 12.2% 8.7s 220.0MB/s 4.9s 390.5MB/s
zstd 266MB 13.9% 11.9s 161.1MB/s 3.5s 539.5MB/s
pigz (x4) 232MB 12.1% 13.1s 146.1MB/s 4.2s 455.6MB/s
gzip 232MB 12.1% 39.1s 48.9MB/s 9.2s 208.0MB/s
lbzip2 (x4) 188MB 9.9% 42.0s 45.6MB/s 13.2s 144.9MB/s
pbzip2 (x4) 189MB 9.9% 117.5s 16.3MB/s 20.1s 95.2MB/s
bzip2 189MB 9.9% 273.4s 7.0MB/s 42.8s 44.7MB/s
pixz (x4) 132MB 6.9% 456.3s 4.2MB/s 7.9s 242.2MB/s
xz 132MB 6.9% 1027.8s 1.9MB/s 17.3s 110.6MB/s
brotli (q11) 141MB 7.4% 4979.2s 0.4MB/s 3.6s 531.6MB/s
Если 16 ядер вашего сервера простаивают достаточно, чтобы все можно было использовать для сжатия, pbzip2 вероятно, даст вам очень значительное ускорение. Но вам все еще нужно больше скорости, и вы можете терпеть файлы большего размера на ~ 20%, gzip вероятно, ваш лучший выбор.
Обновить: я добавил brotli (см. ответ TOOGAM) результаты в таблицу. brotlis настройка качества сжатия очень сильно влияет на степень сжатия и скорость, поэтому я добавил три параметра (q0, q1, и q11). По умолчанию q11, но он очень медленный и все же хуже, чем xz. q1 хотя выглядит очень хорошо; та же степень сжатия, что и gzip, но в 4-5 раз быстрее!
Обновить: Добавлено lbzip2 (см. комментарий gmathts) и zstd (Комментарий Джонни) к таблице и отсортировал его по скорости сжатия. lbzip2 ставит bzip2 семья снова в бегах, сжав в три раза быстрее, чем pbzip2 с отличной степенью сжатия! zstd тоже выглядит разумно, но проигрывает brotli (q1) как в соотношении, так и в скорости.
Мой первоначальный вывод, что простой gzip лучше всего начинает выглядеть почти глупо. Хотя по повсеместности все равно не обыграть;)
Используйте pbzip2.
В руководство говорит:
pbzip2 - это параллельная реализация компрессора файлов с сортировкой блоков bzip2, который использует потоки pthread и обеспечивает почти линейное ускорение на машинах SMP. Вывод этой версии полностью совместим с bzip2 v1.0.2 или новее (то есть: все, что сжато с помощью pbzip2, можно распаковать с помощью bzip2).
Он автоматически определяет количество имеющихся у вас процессоров и соответственно создает потоки.
Некоторые данные:
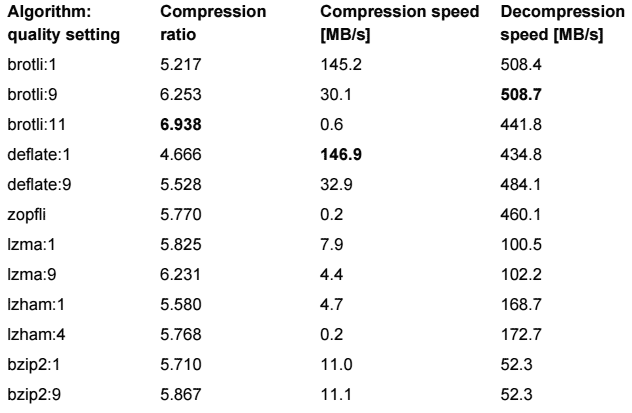
Сравнение алгоритмов сжатия Brotli, Deflate, Zopfli, LZMA, LZHAM и Bzip2
CanIUse.com: особенность: brotli показывает поддержку Microsoft Edge, Mozilla Firefox, Google Chrome, Apple Safari, Opera (но не Opera Mini или Microsoft Internet Explorer).
Сравнение: Brotli vs deflate vs zopfli vs lzma vs lzham vs bzip2
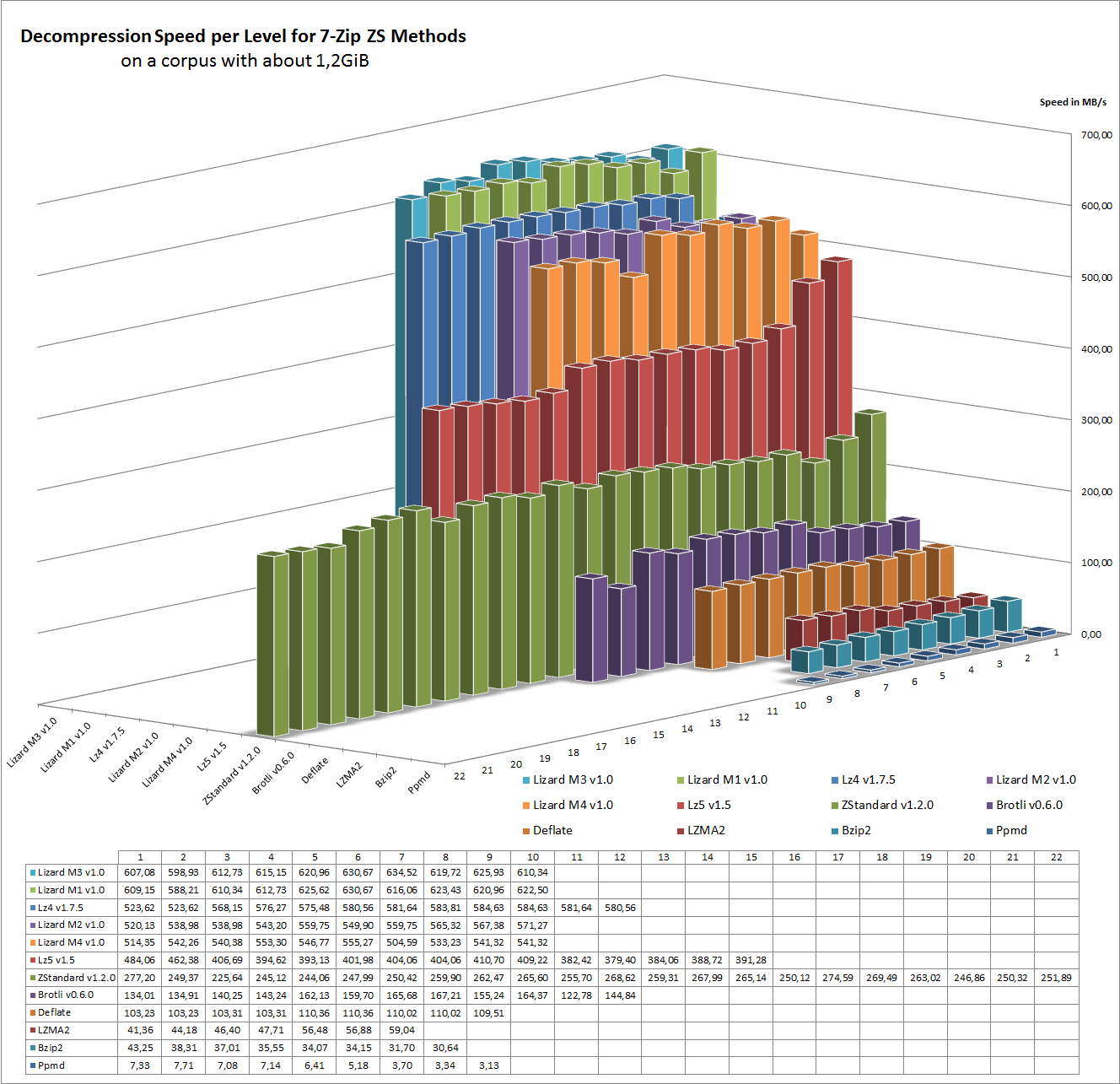
Вы не упомянули операционную систему. Если Windows, 7-Zip с ZStandard (выпуски) - это версия 7-Zip, которая была модифицирована для поддержки использования всех этих алгоритмов.
Использовать zstd. Если этого достаточно для Facebook, вероятно, и для вас.
Если серьезно, то на самом деле довольно хорошо. Сейчас я использую его для всего, потому что он просто работает, и он позволяет вам обменивать скорость на соотношение в больших масштабах (чаще всего скорость в любом случае важнее размера, поскольку хранилище дешево, но скорость является узким местом).
На уровнях сжатия, которые обеспечивают сравнимое общее сжатие с bzip2, это значительно быстрее, и если вы готовы доплатить за процессорное время, вы можете почти добиться результатов, аналогичных LZMA (хотя тогда он будет медленнее, чем bzip2). При несколько худших степенях сжатия это много много быстрее, чем bzip2 или любая другая распространенная альтернатива.
Теперь вы сжимаете дамп SQL, который так же досадно тривиально сжимать, насколько это возможно. Даже самые плохие компрессоры показывают хорошие результаты по таким данным.
Так ты можешь бежать zstd с более низким уровнем сжатия, который запустит десятки раз быстрее и по-прежнему достигать 95-99% того же сжатия этих данных.
В качестве бонуса, если вы будете делать это часто и хотите потратить дополнительное время, вы можете "обучить" zstd компрессор раньше времени, который увеличивает степень сжатия и скорость. Обратите внимание, что для того, чтобы обучение работало хорошо, вам нужно будет кормить его отдельными записями, а не целым. Инструмент работает так, что для обучения требуется множество небольших и в чем-то похожих образцов, а не один огромный объект.
Похоже, что изменение (уменьшение) размера блока может существенно повлиять на время сжатия.
Вот некоторые результаты эксперимента, который я провел на своей машине. Я использовал time команда для измерения времени выполнения. input.txt текстовый файл размером ~ 250 МБ, содержащий произвольные записи json.
Используя стандартный (самый большой) размер блока (--best просто выбирает поведение по умолчанию):
# time cat input.txt | bzip2 --best > input-compressed-best.txt.bz
real 0m48.918s
user 0m48.397s
sys 0m0.767s
Используя наименьший размер блока (--fast аргумент):
# time cat input.txt | bzip2 --fast > input-compressed-fast.txt.bz
real 0m33.859s
user 0m33.571s
sys 0m0.741s
Это было немного неожиданным открытием, учитывая, что в документации говорится:
Скорость сжатия и декомпрессии практически не зависит от размера блока.
{kind=link}
{kind=link}